Kubernetes Fundamentals 2
Table of Contents
Interactive Learning Environment
Advanced concepts such as Services, Configmaps, Secrets, and Persistent Volumes.
All of our labs are powered by Katacoda and are located at this Profile.
Services
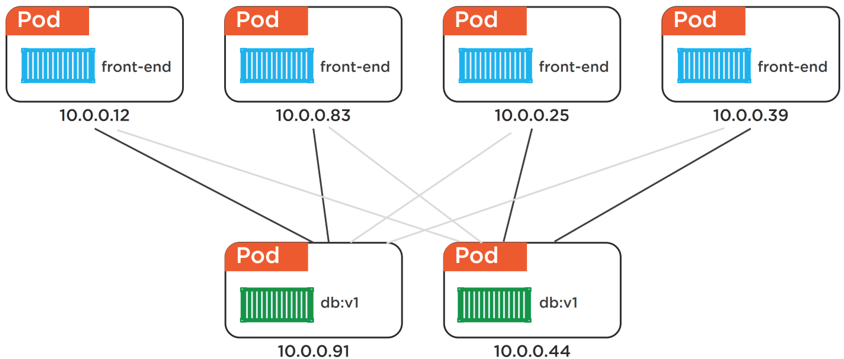
Figure 1: No Labels
Pods are mortal and can die, for instance, if they are deployed via ReplicaSets or Deployments, when they fail, they will get replaced with new Pods somewhere else in the cluster. At this point though these Pods now have totally different IPs. This can also happens when we scale an app as all of the new Pods all execute with their own new IPs. Additionally this can also happen when performing rolling updates etc whereby the process of replacing old Pods with new Pods can result in a lot of IP churn.
The lesson to be learnt here is that we can’t rely on Pod IPs. But we still need to make sure we have access to our services. Assume we’ve got a microservice app with a persistent storage backend that other parts of the app use to store and retrieve data. How would this work if we can’t rely on the IP addresses of the backend Pods. Take a look at Figure 1. This shows a simplified version of a two-tier app with a web front-end that talks to a persistent backend. But it’s all Pod-based, meaning the IPs of the backend Pods can change.
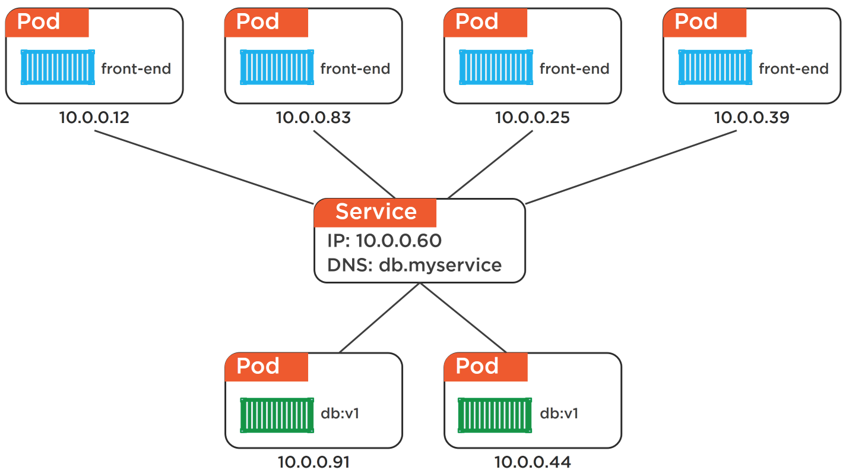
Figure 2: Labels
This is where Services come in to play. Services provide a reliable networking endpoint for a set of Pods. Once a Service object is thrown into the mix, as shown in Figure 2, we can see how the front-end can now talk to the reliable IP of the Service, which in-turn load-balances all requests over the backend Pods behind it. Obviously, the Service keeps track of which Pods are behind it and dynamically updates as Pods are added and removed.
Digging in to a bit more detail. Services are fully fledged objects in the Kubernetes API just like Pods, ReplicaSets, and Deployments. They provide stable DNS, IP addresses, and support TCP and UDP (TCP by default). They also perform simple randomized load-balancing across Pods, though more advanced load balancing algorithms may be supported in the future. This adds up to a situation where Pods can come and go, the Service observes this, automatically updates itself, and continues to provide that stable networking endpoint. The same applies if we scale the number of Pods all the new Pods, with the new IPs, get seamlessly added to the Service and load-balancing keeps working.
Service: A stable network abstraction point for multiple Pods, and it provides basic load balancing.
ConfigMaps
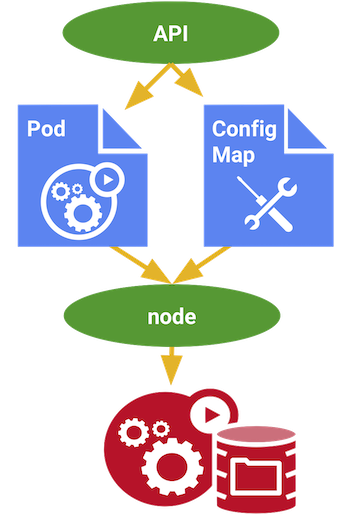
Figure 3: ConfigMaps
ConfigMaps allow you to decouple configuration artifacts from image content to keep containerized applications portable. This is achieved by binding configuration files, command-line arguments, environment variables, port numbers, and other configuration artifacts to your Pods’ containers and system components at runtime. ConfigMaps allow you to separate your configurations from your Pods and components, which helps keep your workloads portable, makes their configurations easier to change and manage, and prevents hardcoding configuration data to Pod specifications.
ConfigMaps are useful for storing and sharing non-sensitive, unencrypted configuration information. To use sensitive information in your clusters, you must use Secrets.
Secrets
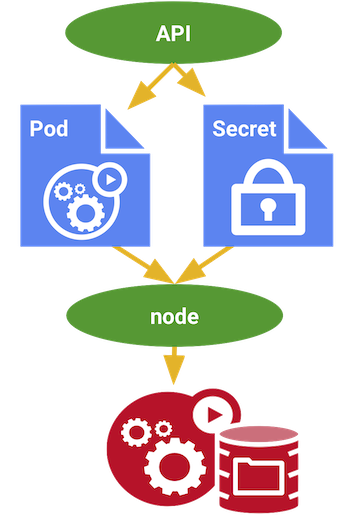
Figure 4: Secrets
Secrets are secure objects which store sensitive data, such as passwords, OAuth tokens, and SSH keys, in your clusters. Storing sensitive data in Secrets is more secure than plaintext ConfigMaps or in Pod specifications. Using Secrets gives you control over how sensitive data is used, and reduces the risk of exposing the data to unauthorized users.
You can also encrypt Secrets at the application layer using a key you manage in Cloud KMS. To learn more, see Application-layer Secrets Encryption.
PersistentVolumes / PersistentVolumeClaims
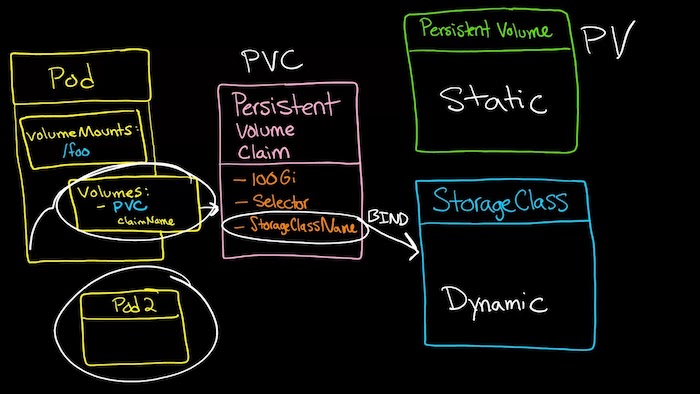
Figure 5: PVC
PersistentVolume resources are used to manage durable storage in a cluster. PersistentVolumes can also be used with other storage types like NFS. Unlike Volumes, the PersistentVolumes lifecycle is managed by Kubernetes. PersistentVolumes can be dynamically provisioned; the user does not have to manually create and delete the backing storage.
PersistentVolumes are cluster resources that exist independently of Pods. This means that the disk and data represented by a PersistentVolume continue to exist as the cluster changes and as Pods are deleted and recreated. PersistentVolume resources can be provisioned dynamically through PersistentVolumeClaims, or they can be explicitly created by a cluster administrator.
A PersistentVolumeClaim is a request for and claim to a PersistentVolume resource. PersistentVolumeClaim objects request a specific size, access mode, and StorageClass for the PersistentVolume. If a PersistentVolume that satisfies the request exists or can be provisioned, the PersistentVolumeClaim is bound to that PersistentVolume.
Pods use claims as Volumes. The cluster inspects the claim to find the bound Volume and mounts that Volume for the Pod. Portability is another advantage of using PersistentVolumes and PersistentVolumeClaims. You can easily use the same Pod specification across different clusters and environments because PersistentVolume is an interface to the actual backing storage.
Ingress
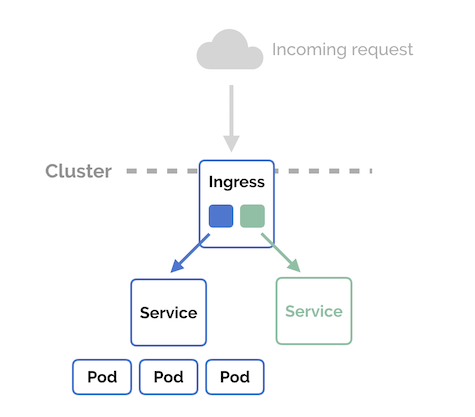
Figure 5: Ingress
An Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource. We expose the ingress controller to the internet, and it will route requests to the applications based on hostname, path or other conditions.
Note: An Ingress does not expose arbitrary ports or protocols. Exposing services other than HTTP and HTTPS to the internet typically uses a service of type
Service.Type=NodePortorService.Type=LoadBalancer.